
Bízzuk az AI-ra a felhasználói visszajelzések elemzését?
Négy nyelvi modell eredményeit vetettük össze emberektől származó elemzésekkel

A felhasználók folyamatosan mesélnek szolgáltatásokról, appokról, termékekről: Google-értékelésekben, app-áruházakban, fórumokon, közösségi médiában vagy épp ügyfélszolgálati felületeken. Ezek nem kérdőívekre adott válaszok, hanem önkéntes, spontán vélemények. Éppen ezért nagyon értékes adatok lehetnek, ugyanakkor zajosak is. Ahhoz, hogy termék- vagy szolgáltatásfejlesztési döntésekhez is használhatók legyenek, érdemes ezeket az organikus visszajelzéseket valamilyen módon strukturálni.
A kihívást tehát nem az adatok hiánya, hanem azok értelmezése jelenti.
Miről is beszélnek valójában az emberek? Milyen témák, panaszok, fejlesztési igények rajzolódnak ki a szövegekből? Erre akkor kapunk igazán áttekinthető választ, ha a visszajelzésekben megjelenő mintázatokat feltárjuk, majd a szövegeket ennek megfelelően címkézzük és kategorizáljuk. Kevés adatot emberi munkával is hatékonyan fel lehet dolgozni, de nagy mennyiségnél és rendszeres elemzésnél felmerül a csábító lehetőség: rábízhatjuk-e a munkát egy nyelvi modellre? És ha igen: melyikre, milyen módon, és milyen buktatókkal számoljunk? Ezekre kerestük a választ egy banki mobilapp felhasználói értékelésein keresztül.
Módszer
Előre megadott kategóriák szerint címkéztettünk 100 db felhasználói visszajelzést négy nyelvi modellel (GPT/ChatGPT, Sonnet/Claude, RoBERTa, LLaMA) és három emberrel. A nyelvi modellekkel három alkalommal is elvégeztettük ugyanazt a feladatot. Így nem csak azt tudtuk megvizsgálni, hogy az AI megoldása mennyire hasonlít az emberi logikára, hanem a modellek konzisztenciáját is leteszteltük (vagyis, hogy az egyes modellek meg tudják-e ismételni a saját megoldásukat).
A ChatGPT és a Claude prompt alapján végezte el a címkézési feladatot, a RoBERTa és a LLaMA modelleket az NLP Cloud kategorizációs platformján keresztül használtuk, az emberek pedig írásos instrukciót kaptak.
NLP Cloud
Az NLP Cloud egy online platform, amely különböző mesterséges intelligencia modelleket tesz hozzáférhetővé mind weboldalon, mind API-n keresztül. Többféle feladatra kínál eszközt, ezek egyike a szövegek kategorizálására szolgáló modul. Ezen keresztül a RoBERTa és LLaMA modelleket (a Claude-dal és a ChatGPT-vel ellentétben) nem szöveges utasítással, hanem API-n keresztül programkóddal irányítottuk.
A ChatGPT és a Claude promptján egy körben iteráltunk, így ezek a modellek két körben, tehát 2*3 alkalommal végezték el a címkézést (lásd: 1. táblázat).
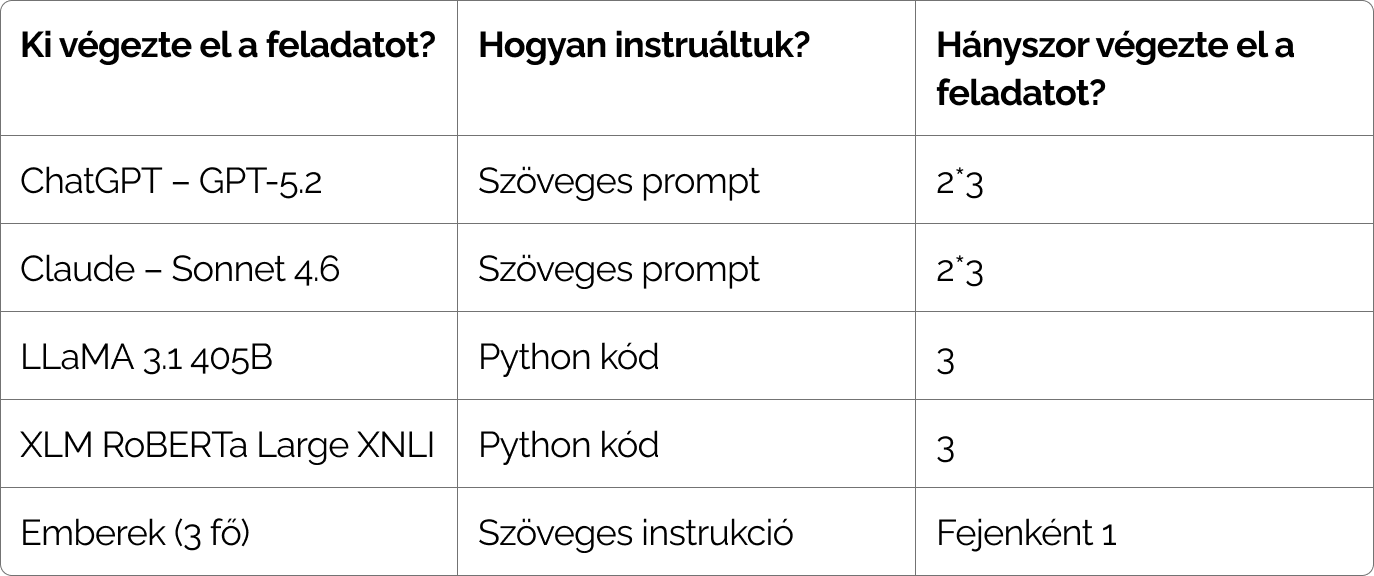
1. táblázat: Használt modellek és instrukciók típusa
1. tanulság, avagy az instrukciók megfogalmazásának jelentősége
Az első körben a ChatGPT 100%-os konzisztenciát produkált, vagyis mindhárom futtatásban pontosan ugyanazt a megoldást adta. Ez első pillantásra nagyon jó eredménynek tűnt, de valójában rossz okból volt ennyire stabil: a modell belefutott a lehorgonyzási torzításba, gyakorlatilag mindent ugyanabba az egyetlen kategóriába sorolt, a szövegek tartalmától függetlenül.
A Claude ugyanezzel a prompttal az elvárásaink szerint működött. Több kategóriát is használt, és az eredményei 83%-ban voltak egyezők a három futtatás között.
Lehorgonyzási torzítás (anchoring bias)
Az a jelenség, amikor az elsőként kapott információ (a “horgony”) aránytalanul erősen befolyásolja a későbbi ítéleteket és döntéseket, még akkor is, ha a horgony részben vagy teljesen irreleváns. (További példa és kutatás az AI lehorgonyzási torzítása kapcsán ezen a linken.)
Ezután finomítottuk a promptot, és ezt is háromszor lefuttattuk mindkét modellel. Ebben a második körben a ChatGPT már csak egy futtatásban ragadt bele a lehorgonyzásba, a másik két futtatás változatosabb címkézést adott. Emiatt viszont a három futtatás eredménye erősen eltért egymástól, így a ChatGPT konzisztenciája ebben a körben 10% lett. Ez strukturált, ismételhető elemzési feladatoknál nem elfogadható.
A Claude-nál a finomított prompt rontott a stabilitáson: a konzisztencia 83%-ról 63%-ra csökkent (lásd: 2. táblázat). Ez is mutatja, hogy ugyanarra a promptra és ugyanarra a módosításra a különböző modellek eltérően reagálhatnak.
A LLaMA és a RoBERTa modelleket nem szöveges prompttal futtattuk, hanem egy kifejezetten szövegkategorizációra kialakított megoldással, Python kódon keresztül. Itt a LLaMA 95%-os, a RoBERTa pedig 100%-os konzisztenciát mutatott.
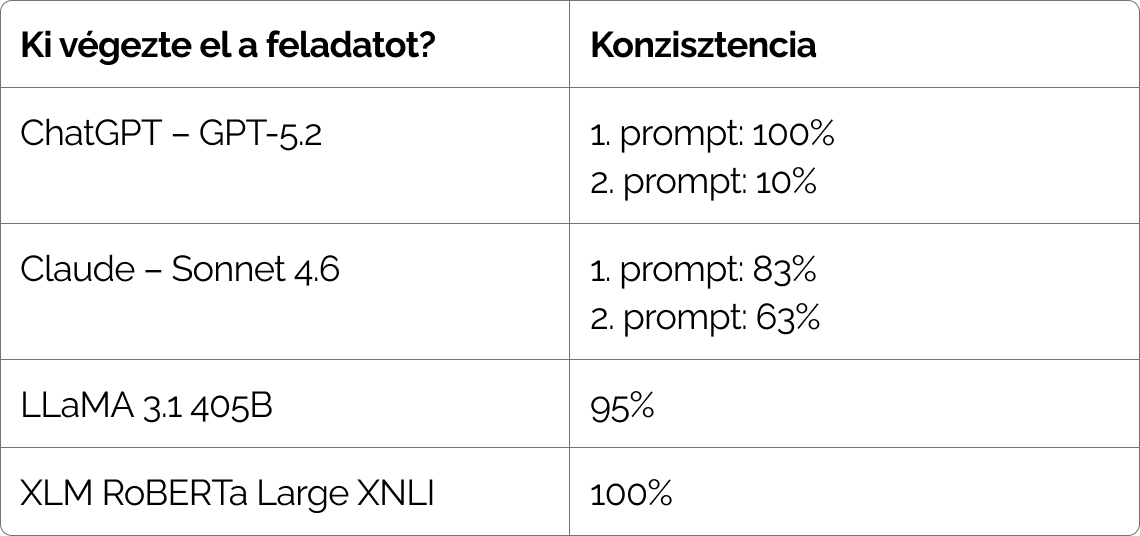
2.táblázat: Modellek konzisztenciája három futtatás alapján
Az eredmények konzisztenciáját nagyban befolyásolja, hogyan futtatjuk és milyen keretek közé szorítjuk a feladatot. A chat-alapú generatív modellek (ChatGPT, Claude) érzékenyebbek az apró megfogalmazásbeli különbségekre, ezért ugyanaz a feladat több futtatásban eltérő címkézést adhat. A LLaMA, bár a ChatGPT és a Claude modelljeihez hasonlóan generatív modell, nálunk strukturált módban (kategorizációs API-n keresztül, kóddal, kötött címkekészlettel) futott, ezért sokkal stabilabb eredményt kaptunk. A RoBERTa a másik három modellhez képest más elven működik, ez kifejezetten osztályozásra optimalizált. És mint ilyen, a 100%-os konzisztencia elvárható ettől a modelltől.
2. tanulság, avagy konzisztencia ≠ minőség
A ChatGPT-nél a tökéletes konzisztencia fals eredményeket takart. Ezzel szemben a RoBERTa úgy volt 100%-ban stabil, hogy az elvárásunknak megfelelően, többféle címkét használt. Ugyanakkor, a RoBERTa megoldását összevetettük az emberi címkézés eredményeivel (ehhez a három személy konszenzusos címkézését használtuk), és a kettő csupán 25%-ban egyezett.
Tehát a RoBERTa modell stabil volt, de az emberi gondolkodástól nagyban eltért a megoldása.
3. tanulság, avagy az emberek sem mindig értenek egyet egymással
Mielőtt az AI-modellektől elvárjuk a konzisztens és számunkra is értelmes megoldást, érdemes megnézni, hogyan teljesítenek ugyanezen a címkézési feladaton az emberek. Három értékelő dolgozott egymástól függetlenül ugyanazon a 100 felhasználói visszajelzésen, ugyanazzal a 10 db, előre meghatározott címkével.
A három személy megoldását páronként összehasonlítottuk, és azt találtuk, hogy ezek 44%, 46%, illetve 58%-ban voltak azonosak egymással (lásd: 1. ábra). Teljes egyetértés (ahol mindhárom személy ugyanazt a címkét választotta) a szövegek egyharmadánál volt, teljes eltérés (ahova három különböző címke kerülte került) pedig az esetek 20%-ában.
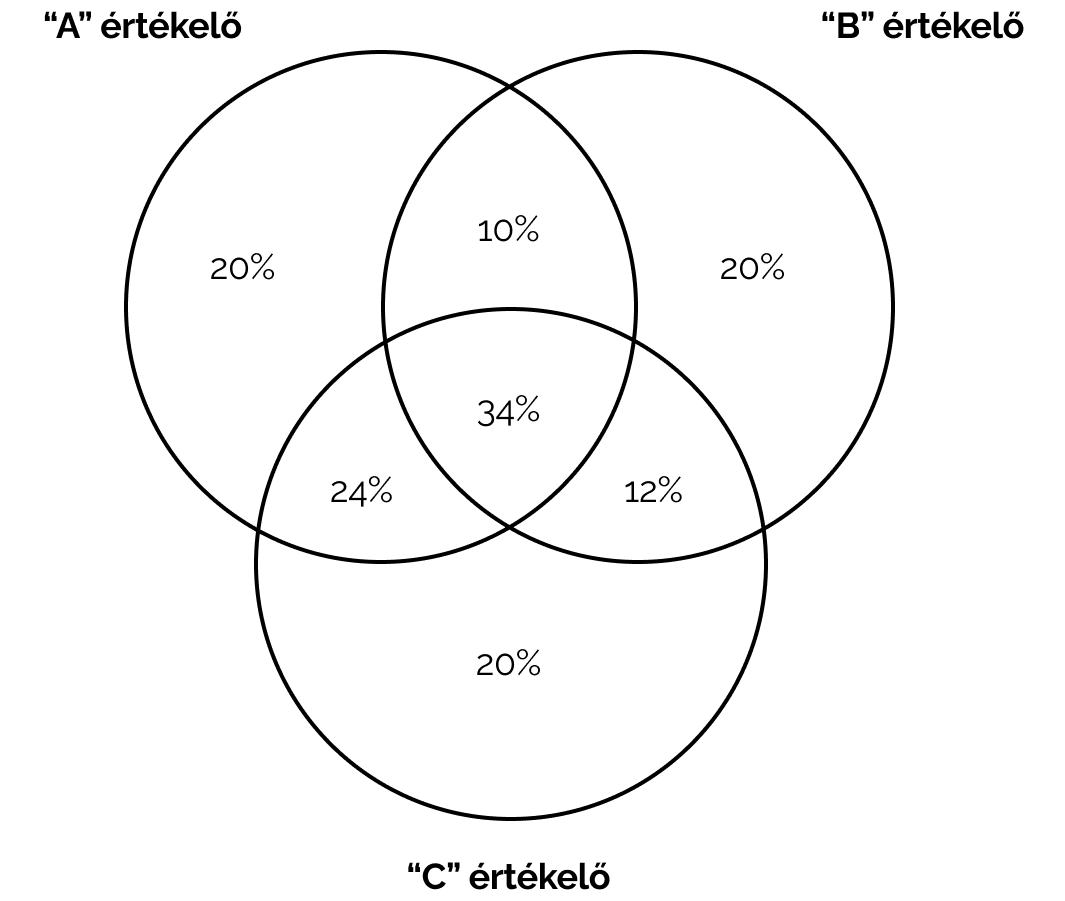
1. ábra: A három értékelő személy megoldása közötti átfedések
Ez nem a figyelmetlenség jele, hanem a címkék pontosságának, egyértelműségének kérdése. Nemcsak a címkék elnevezése számít, hanem az is, hogy hány címke illik egy adott szövegre. Ha egyes szövegekre több címke is illik, de csak egy választható közülük, az nem kedvez az egyértelmű döntésnek. A kategóriarendszer pontossága és egyértelműsége mind az emberek, mind az AI esetében kulcskérdés.
Ahol az emberek döntése eltérő, ott az AI-tól sem várható egységes válasz.
Eredmények összegzése
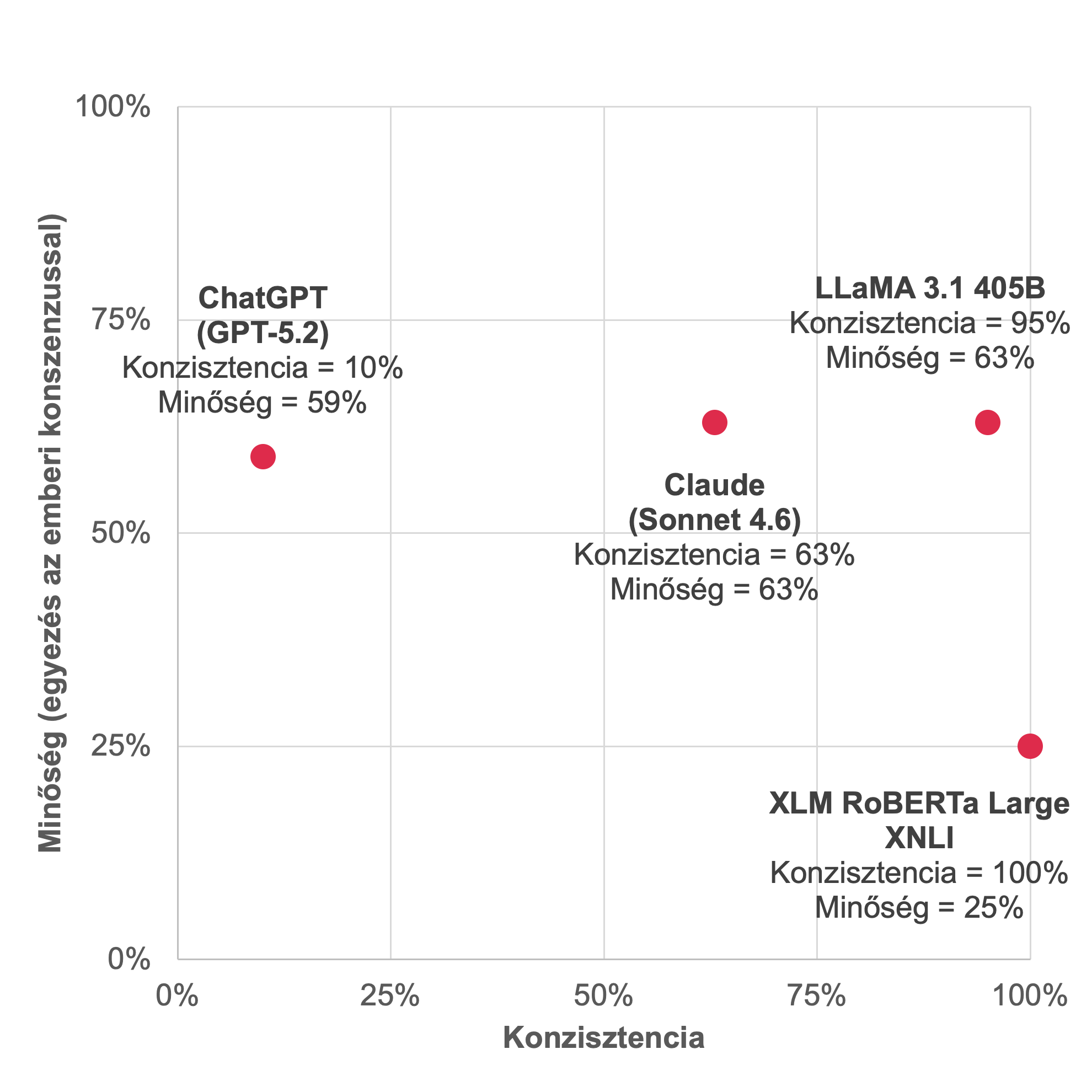
2. ábra: A vizsgált modellek megoldásainak konzisztenciája és minősége (az emberi megoldáshoz viszonyítva)
A négy modell közül a LLaMA nyújtotta a legjobb egyensúlyt konzisztencia és minőség szempontjából: 95%-ban volt konzisztens és a megoldása 63%-ban egyezett az emberi címkézéssel (lásd: 2. ábra). A Claude megoldása szintén 63%-ban egyezett az emberekével, de ez a modell kevésbé volt konzisztens (63%).
Talán kevésnek tűnhet, hogy az AI megoldások maximum 63%-ban egyeztek az emberekével. Ugyanakkor az emberek sem gondolkodtak egyformán, maximum 58%-ban jutottak azonos döntésre a címkézés során.
Ennek fényében a 60% körüli AI–ember megfelelés nem gyenge teljesítmény, hanem a különböző emberi gondolkodásmódok közötti egyezés szintjének megközelítése.
Mit jelent ez a gyakorlatban?
Nem azt, hogy az AI megbízhatatlan, és nem is azt, hogy az embereket kiváltja. Inkább azt, hogy a kérdést másképp kell feltenni: nem "Melyik AI a legjobb?", hanem "Melyik feladatra, milyen feltételek mellett, melyik modell alkalmas?".
Ha nagy mennyiséget kell automatizáltan feldolgozni, a LLaMA strukturált módban a legkiegyensúlyozottabb választás.
Ha gyors, exploratív elemzést szeretnénk, és az eredményt emberi szem nézi át, a Claude vagy a ChatGPT is elvégezheti a munkát. Ebben az esetben a prompt gondos kidolgozása és tesztelése elengedhetetlen.
Ha a kategóriarendszer jól definiált, a RoBERTa finomhangolás után akár a legjobb megoldás is lehet.
A tartalomcímkézés nem pusztán technológiai kérdés, hanem értelmezési feladat is. A modellek teljesítménye mindig a kategóriarendszer minősége, a feladatmegfogalmazás és az emberi kontextus tükrében értelmezhető igazán.
Az AI a legjobb esetben sem az abszolút igazságot mondja, hanem az emberi konszenzust közelíti meg.
Szerző: Székely Zsuzsa, a Works Experience Designer kollégája